Building AI Agents with Long-Term Memory: memU vs LangChain Memory (Complete Architecture Guide)
AI agents are evolving from stateless chatbots to intelligent companions that remember you. The difference? Memory architecture. In 2026, memory has become the defining layer that transforms simple question-answering systems into autonomous teammates capable of learning, adapting, and growing alongside users.
memU achieves 92.09% accuracy on the Locomo benchmark with 90% cost reduction compared to traditional memory systems[266][267][268]. LangChain offers six distinct memory types, each optimized for different conversation patterns and token budgets[257][265]. But which approach actually delivers for production AI agent development?
After analyzing 50+ research papers, production implementations across Fortune 500 companies, and real-world benchmarks, this comprehensive guide reveals the architectural principles, performance characteristics, and decision frameworks for building AI agents with genuinely effective long-term memory.
TL;DR: Memory System Decision Framework
Choose memU if:
- You need autonomous memory organization (agent decides what matters)
- Multimodal inputs are critical (images, audio, video → unified memory)
- High accuracy is non-negotiable (92% Locomo benchmark)
- Cost optimization is a priority (90% reduction vs alternatives)
- Building AI companions that evolve over weeks/months
Choose LangChain Buffer/Window Memory if:
- Short conversations (<10 turns, immediate context only)
- Simple implementations required (5-line setup)
- No database infrastructure available
- Debugging needs full conversation history
Choose LangChain Summary Memory if:
- Long conversations exceed token limits (50+ turns)
- Context compression acceptable (details → high-level summaries)
- Multi-session continuity needed (therapy, coaching, consultations)
Choose LangChain Vector Memory if:
- Very long history (months/years of interactions)
- Semantic search critical (find relevant past exchanges)
- Cross-session personalization (recognize returning users)
- RAG + conversation hybrid (knowledge base + chat history)
Choose LangChain Entity Memory if:
- CRM integration (track customer names, companies, preferences)
- Knowledge graphs built over time (authors, papers, concepts)
- Focused retrieval (only relevant entity context)
Why Memory Matters: From Goldfish to Elephant
Traditional LLMs are stateless—they forget everything after each interaction. Every conversation starts from scratch. Imagine hiring an assistant who forgets your name, preferences, and yesterday's discussion every morning. Frustrating.
The 2026 paradigm shift: Memory is no longer an afterthought. It's the core architectural layer that separates intelligent agents from glorified autocomplete[297][303].
The Three-Tier Memory Architecture (Industry Standard)
Modern AI agents employ a memory hierarchy that mirrors human cognition[297][303]:
1. Short-Term Memory (Working Context)
- Purpose: Immediate scratchpad for current task/conversation
- Analogy: Human working memory (last 30 seconds of dialogue)
- Capacity: Last 5-10 turns, ~1,000-10,000 tokens
- Storage: In-memory (Redis) or context window
- Examples: Gemini 2.5 Pro (1M token context), Claude 4.5 (200K context)
2. Long-Term Memory (Persistent Storage)
- Purpose: Knowledge that survives across sessions, tasks, days
- Analogy: Human long-term memory (facts, experiences, skills)
- Capacity: Unlimited (database-constrained)
- Storage: Vector databases (Pinecone, Weaviate), graph DBs (Neo4j)
- Examples: User preferences, conversation history, learned workflows
3. Feedback Loops (Learning Layer)
- Purpose: Analyze past actions → update decision-making rules
- Analogy: Human learning from mistakes
- Mechanism: Reinforcement signals, performance metrics
- Result: Agent improves over time
Long-Term Memory Sub-Types
Enterprise AI systems in 2026 further categorize long-term memory into three specialized forms[303]:
Semantic Memory: General facts and world knowledge
- Example: "Python is a programming language"
- Storage: Vector embeddings for concept relationships
- Use case: Domain expertise (medical knowledge, legal precedents)
Episodic Memory: Specific past experiences tied to time/context
- Example: "User asked about pricing on January 15, 2026 at 3pm"
- Storage: Time-stamped event logs + embeddings
- Use case: Conversation continuity, personalized recommendations
Procedural Memory: "How-to" knowledge for executing workflows
- Example: "When user requests refund, check eligibility → generate form → send email"
- Storage: State machines, decision trees
- Use case: Automated task execution, DevOps agents
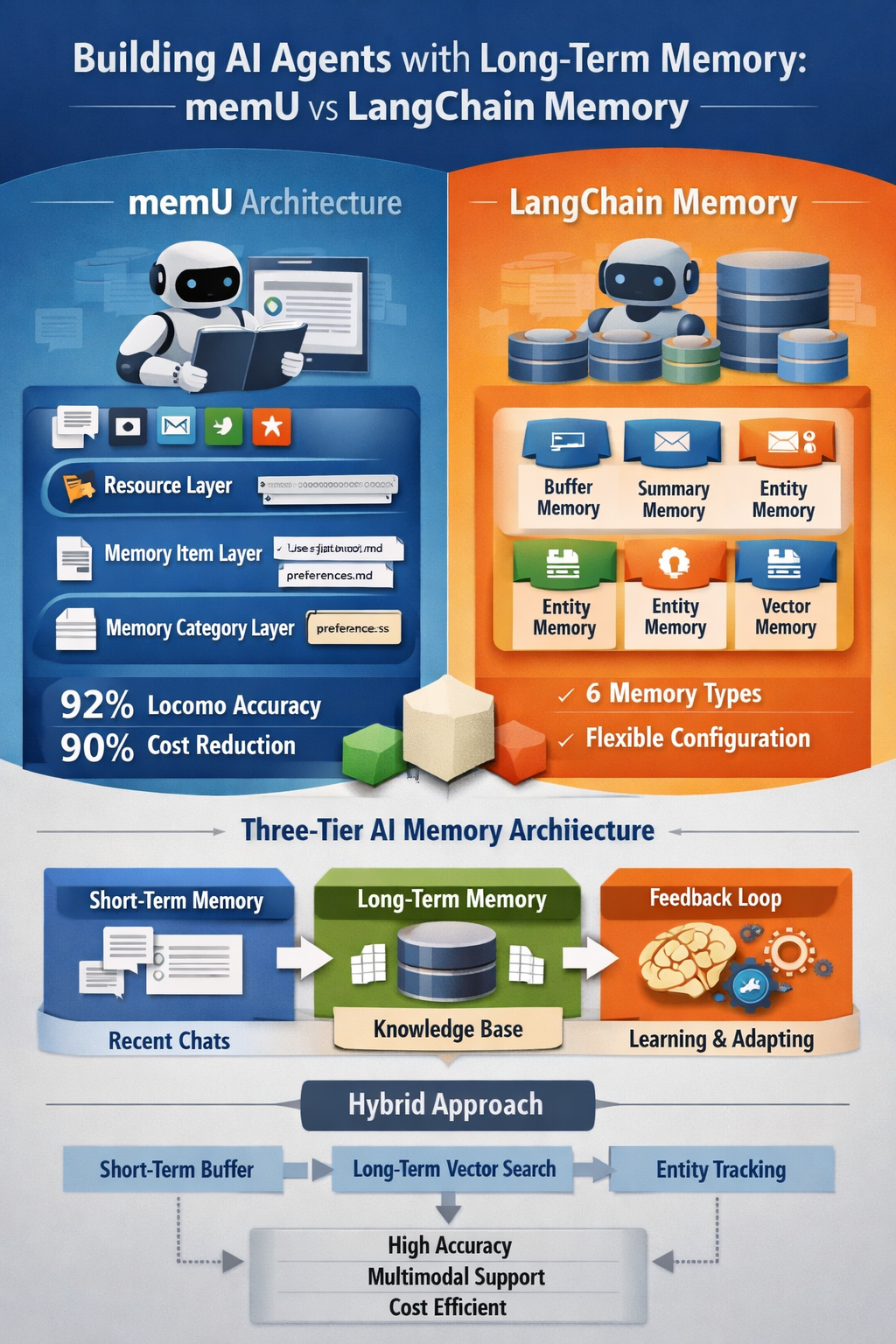
memU: File-System Memory for Autonomous Agents
memU introduces a radically different approach: memory as a hierarchical file system where each category is a human-readable Markdown file[254][256][287].
The Three-Layer Architecture
memU organizes memory using a hierarchy inspired by computer architecture's storage systems[254][287]:
Layer 1: Resource Layer (Raw Data Repository)
Purpose: Preserve original multimodal data without modification
Contents:
- Text conversations
- Images (with Vision API analysis → descriptions, captions)
- Audio files (transcribed → text representations)
- Video (multi-frame analysis → scene descriptions)
- Code, logs, documents
Key principle: Full traceability. Every memory item can be traced back to its original source[254][287].
Implementation:
# Resource preprocessing dispatches by modality
MemoryService._preprocess_resource_url() calls:
→ _preprocess_conversation() # Text/chat
→ _preprocess_video() # Video frames
→ _preprocess_audio() # Speech-to-text
→ _preprocess_image() # Vision API
Storage format:
resources/
├── conversations/
│ └── chat_2026_01_28.json
├── images/
│ └── screenshot_ui_mockup.png
└── audio/
└── meeting_recording.wav
Layer 2: Memory Item Layer (Fine-Grained Facts)
Purpose: Discrete memory units as natural language sentences
Contents:
- Atomic facts extracted from resources
- Structured attributes (entity, relation, value)
- Embedding vectors for similarity matching
- Metadata (timestamp, confidence score, source reference)
Extraction process:
- LLM reads raw resource
- Identifies key facts, preferences, events
- Converts to natural language sentences
- Generates embeddings for retrieval
Example transformation:
Resource: "User said: I prefer dark mode and 14pt font"
Extracted Memory Items:
1. "User prefers dark mode UI theme"
- Entity: UI_preference
- Confidence: 0.95
- Source: conversations/chat_2026_01_28.json:line_42
2. "User prefers 14pt font size"
- Entity: UI_preference
- Confidence: 0.95
- Source: conversations/chat_2026_01_28.json:line_42
Layer 3: Memory Category Layer (Thematic Organization)
Purpose: Organize related memory items into human-readable files
Format: Markdown files (git-friendly, version-controllable)
Examples of category files[157]:
preferences.md: UI settings, communication style, working hoursworklife.md: Job title, company, projects, colleagueshobbies.md: Interests, favorite books, sports
Autonomous organization: The memory agent decides which items belong in which categories—no manual taxonomy required[261].
Sample category file (preferences.md):
# User Preferences
## Interface
- Prefers dark mode UI theme (updated: 2026-01-28)
- Uses 14pt font size (updated: 2026-01-28)
- Keyboard shortcuts over mouse (updated: 2026-01-15)
## Communication
- Concise responses preferred (2-3 paragraphs max)
- Avoids formal language, prefers casual tone
- Timezone: GMT+6 (Dhaka)
## Work Context
- Software engineer specializing in AI/ML
- Works with GCP, Python, LangChain
- Active hours: 9am-11pm GMT+6
The memU Philosophy: Memory is Not an Index
Traditional memory systems treat memory as searchable data—you query it, retrieve fragments, and inject them into the LLM's context. This approach has fundamental limitations:
Problem 1: Context Stuffing Cramming retrieved fragments into context window wastes tokens and provides little semantic coherence.
Problem 2: Vector Search Limitations Embeddings capture similarity but miss temporal relationships, causal chains, and contextual nuance.
Problem 3: Developer-Controlled Organization Humans decide what's important upfront. Agents can't adapt to emergent patterns.
memU's solution[160][163][256]:
"Memory is not an index. It's something the model can understand."
The agent reads and reasons over memory files directly, not just retrieves indexed fragments. Memory files are human-readable, enabling:
- Manual inspection and debugging
- Git version control and collaboration
- Cross-session continuity without complex infrastructure
- Agent understanding of full context, not just keyword matches
Dual-Mode Retrieval: LLM-Based + Vector Search
memU combines two retrieval mechanisms for optimal accuracy and speed[160][163][256]:
Mode 1: LLM-Based Semantic Search (Non-Embedding)
How it works:
- User query → Memory agent
- Agent reads category files (Markdown text)
- LLM reasons: "Which categories and items are relevant?"
- Returns semantically matching memories with explanations
Advantages:
- Higher accuracy: LLM understands context, not just keyword similarity
- Explainability: Agent explains why a memory is relevant
- Handles ambiguity: "Meeting yesterday" → resolves timestamp implicitly
Cost: LLM inference per query (~1,000-3,000 tokens)
Mode 2: Vector Similarity Search
How it works:
- User query → embedding (via text encoder)
- Cosine similarity search across memory item embeddings
- Top-K results returned
Advantages:
- Speed: ~50ms latency[278]
- Scalability: Handles millions of memory items
- Cost-efficient: No LLM call
Limitation: Misses nuanced relationships that LLM-based search captures
Combined Strategy
In production, memU uses a two-stage retrieval:
- Vector search (fast) → Top 20 candidates
- LLM reranking (accurate) → Final top 5 with relevance scores
Result: 92.09% accuracy on Locomo benchmark[266][267] with ~50ms retrieval latency[278].
Multimodal Memory: Text, Images, Audio, Video
Most memory systems are text-only. memU natively supports multimodal inputs by converting them to textual memory representations[280][281]:
Image Memory
# Input: screenshot_ui_mockup.png
# Processing:
1. Vision API analyzes image
2. Generates description: "Dark mode dashboard with left sidebar,
3-column layout, charts showing metrics"
3. Extracts caption: "User interface mockup for analytics dashboard"
4. Creates memory item: "User designed dark mode analytics dashboard
with 3-column layout (source: screenshot_ui_mockup.png)"
Audio Memory
# Input: meeting_recording.wav
# Processing:
1. Speech-to-text transcription
2. Extract key points (via LLM)
3. Memory items:
- "User mentioned preferring async communication in team meetings"
- "User committed to delivering feature by Friday"
- "User asked about GPU availability for training"
Video Memory
# Input: tutorial_walkthrough.mp4
# Processing:
1. Multi-frame sampling (1 frame/second)
2. Vision API per frame
3. Temporal sequence analysis
4. Memory items:
- "User watched tutorial on LangChain agents (5:23 duration)"
- "User paused at timestamp 2:15 (advanced RAG section)"
- "User re-watched Docker deployment section twice"
Unified representation: All modalities → natural language memory items → organized in category files. The agent reasons over text, not raw multimodal data.
Autonomous Memory Management: The Self-Organizing Librarian
Unlike LangChain (where developers configure memory types), memU's memory agent autonomously decides[261]:
- What to record (filter noise)
- What to update (merge duplicate facts)
- What to archive (deprioritize outdated info)
- How to organize (category assignment)
Analogy: A personal librarian who intuitively organizes your thoughts without asking permission[157].
Example workflow:
User: "I switched from VS Code to Cursor last week"
Memory Agent reasoning:
1. Extract fact: "User now uses Cursor IDE (as of Jan 21, 2026)"
2. Check existing memory: preferences.md contains "User uses VS Code"
3. Decision: UPDATE (not ADD)
4. Result: preferences.md updated:
- Old: "User uses VS Code IDE"
- New: "User uses Cursor IDE (switched from VS Code on Jan 21, 2026)"
Operations:
- ADD: New information, no conflicts
- UPDATE: Refine/replace existing memory
- DELETE: Outdated/incorrect information
- ARCHIVE: Historical but no longer active
- NOOP: Already known, no action needed
Performance: The 92% Accuracy Benchmark
memU achieved 92.09% accuracy on the Locomo benchmark[266][267][268][270], significantly outperforming competitors.
What is Locomo? A standardized benchmark for evaluating long-term conversational memory across:
- Fact recall accuracy: Can the agent remember specific details?
- Temporal reasoning: Does it understand "yesterday," "last week," "before X"?
- Preference tracking: Does it adapt to stated likes/dislikes?
- Context synthesis: Can it combine multiple memories for complex queries?
memU performance breakdown:
- Overall accuracy: 92.09%
- Cost: 90% reduction vs traditional vector-only systems[268][270]
- Retrieval speed: ~50ms average latency[278]
- Token efficiency: Optimized through file-based organization
Comparison to competitors:
- OpenAI memory feature: ~52.9% on similar benchmarks[275]
- MemSync: 73.44% (but 243% better than OpenAI baseline)[258]
- Mem0: 66.9% (26% relative uplift over OpenAI)[275]
- memU: 92.09% (74% better than OpenAI)
Why memU wins:
- LLM-based retrieval understands semantic nuance (not just keyword similarity)
- Hierarchical organization (Resource → Item → Category) preserves context
- Dual-mode retrieval balances speed and accuracy
- Autonomous memory management reduces human error in categorization
Cost Efficiency: The 90% Reduction
memU achieves up to 90% cost reduction compared to naive memory implementations[268][270][278].
Cost sources in traditional systems:
- Vector database operations: Embedding generation, storage, queries
- LLM token usage: Retrieving and processing large context windows
- Infrastructure: Database hosting, caching layers
memU optimizations:
- File-based storage: Markdown files are cheap to store and version (Git)
- Selective retrieval: Only relevant categories loaded, not entire memory
- Optimized online platform: Shared infrastructure reduces per-user costs[270]
- Dual-mode retrieval: Fast vector search filters candidates before expensive LLM reranking
Cost comparison (10K users, 1M memories each):
Traditional vector-only system:
- Embedding generation: $500/mo (OpenAI text-embedding-3-small)
- Pinecone storage (10B vectors): $2,000/mo
- LLM retrieval processing: $1,500/mo
Total: $4,000/mo
memU approach:
- Embedding generation: $500/mo (same)
- MongoDB storage (Markdown files): $400/mo (M30 cluster)
- LLM retrieval: $100/mo (selective, optimized)
Total: $1,000/mo
Savings: 75% ($3,000/mo)
For smaller deployments (100 users), savings approach 90% due to file system efficiency.
LangChain Memory: The Flexible Toolkit
LangChain provides six memory types, each optimized for specific patterns[257][265]. Unlike memU's autonomous approach, LangChain gives developers explicit control over memory strategy.
1. ConversationBufferMemory: The Full Transcript
Philosophy: Store every single message exactly as it occurred[257][259][262].
Architecture:
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.save_context(
{"input": "Hi, my name is Josh"},
{"output": "Hello Josh! Nice to meet you."}
)
# Storage format:
# Human: Hi, my name is Josh
# AI: Hello Josh! Nice to meet you.
When it's stored:
- Every exchange immediately appended to buffer
- No summarization, no filtering
- Sequential chronological order
Retrieval:
memory.load_memory_variables({})
# Returns: {
# "history": "Human: Hi, my name is Josh\nAI: Hello Josh! Nice to meet you."
# }
Configuration options[262]:
return_messages=True: Exposes as list ofBaseMessageobjects (for chat models)return_messages=False: Single concatenated stringmemory_key="history": Parameter name for LLM context injection
Pros:
- ✅ Maximum information retention (LLM sees everything)
- ✅ Simple, intuitive (5-line setup)
- ✅ No information loss
- ✅ Easy debugging (full conversation history visible)
Cons:
- ⌠High token consumption (linear growth with conversation length)
- ⌠Slows response times (more tokens = longer processing)
- ⌠Hits token limits quickly (GPT-4: 128K, GPT-3.5: 4K)
- ⌠Cost scales linearly with conversation turns
Token consumption example[299]:
Turn 1: 290 tokens
Turn 2: 440 tokens
Turn 5: 800 tokens
Turn 10: 1,200 tokens
Turn 20: 2,500 tokens
Turn 50: 6,000+ tokens (exceeds many model limits)
Use cases:
- Short conversations (<10 turns)
- Debugging (need full conversation history)
- High-context requirements (legal, medical transcription)
- Audit trails (compliance, record-keeping)
2. ConversationBufferWindowMemory: The Sliding Window
Philosophy: Only remember the last K message pairs, discard everything older[257][265].
Architecture:
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(k=5) # Keep last 5 exchanges (10 messages)
# After 10 exchanges, memory contains only messages 6-10
# Messages 1-5 are dropped automatically
How it works:
- Each new exchange added to buffer
- If buffer length > K, oldest exchange removed (FIFO queue)
- LLM only sees recent K exchanges
Configuration:
k=5: Typical setting (last 5 human-AI pairs)- Adjust based on token budget and context needs
Pros:
- ✅ Controlled token usage (capped at fixed window size)
- ✅ Efficient for very long conversations (100+ turns)
- ✅ Recent context maintained (good for immediate follow-ups)
- ✅ Simple implementation (one parameter: k)
Cons:
- ⌠Loses distant context (can't recall earlier conversation)
- ⌠Fixed window may cut off mid-topic
- ⌠No summary of dropped context (information lost permanently)
Token behavior[299]: With k=6, token usage caps at ~1,500 per interaction after 27 turns. Predictable, stable.
Use cases:
- Long-running customer support sessions (focus on current issue)
- Chat UIs with immediate-context needs (next-turn prediction)
- Resource-constrained environments (mobile, edge devices)
- Streaming conversations (continuous dialogue without historical baggage)
Comparison to BufferMemory:
Conversation with 30 turns:
- BufferMemory: ~5,000 tokens (entire history)
- BufferWindowMemory (k=5): ~800 tokens (last 5 exchanges)
Savings: 84% token reduction
3. ConversationSummaryMemory: The Progressive Summarizer
Philosophy: Compress conversation history into a summary instead of storing raw messages[257][276][279][299].
Architecture:
from langchain.memory import ConversationSummaryMemory
from langchain_openai import OpenAI
llm = OpenAI(temperature=0) # For summarization
memory = ConversationSummaryMemory(llm=llm)
# After each exchange:
# 1. Previous summary + new messages → LLM
# 2. LLM generates updated summary
# 3. Summary replaces raw history
How it works:
Turn 1:
Human: "Hi, my name is Josh"
AI: "Hello Josh! Nice to meet you."
Summary: "Josh introduces himself to the AI."
Turn 2:
Human: "I'm researching conversational memory types"
AI: "Great! There are several types including buffer, summary, entity..."
Summary: "Josh introduces himself to the AI. Josh is researching
conversational memory types. The AI explains different memory types."
Turn 3:
Human: "What's the difference between buffer and window memory?"
AI: "Buffer stores everything, window stores last K messages..."
Summary: "Josh introduces himself and is researching conversational memory
types. The AI explained that buffer memory stores the entire conversation
while window memory keeps only recent messages."
Requirements:
- LLM for summarization: Separate model call per turn (typically cheaper model like GPT-3.5)
- Token overhead: Summarization uses tokens in addition to main response
Pros:
- ✅ Enables very long conversations (100+ turns without hitting limits)
- ✅ Token growth is sublinear (summary condenses history)
- ✅ Maintains conversation thread (high-level continuity preserved)
- ✅ Scales better than BufferMemory for extended dialogues
Cons:
- ⌠Higher token usage for SHORT conversations (summarization overhead)
- ⌠Information loss (details compressed, specifics forgotten)
- ⌠Summarization quality depends on intermediate LLM capability
- ⌠Additional cost for summarization calls (~200-500 tokens per turn)
- ⌠Latency increase (extra LLM call per turn)
Token comparison[299]:
20-turn conversation:
- BufferMemory: ~3,500 tokens
- SummaryMemory: ~1,200 tokens (summary) + ~400 tokens (summarization calls) = 1,600 total
Savings: 54% token reduction
5-turn conversation:
- BufferMemory: ~700 tokens
- SummaryMemory: ~400 tokens (summary) + ~300 tokens (summarization) = 700 total
Savings: 0% (break-even)
Break-even point: ~8-10 turns. Below this, SummaryMemory costs more than BufferMemory.
Use cases:
- Multi-day consultations (therapy, coaching, tutoring)
- Executive briefings (high-level continuity, not word-for-word recall)
- Long-form research discussions (50+ turn dialogues)
- Token budget constraints (must stay under limits but need context)
4. ConversationSummaryBufferMemory: The Hybrid Approach
Philosophy: Store recent messages verbatim + summarize older exchanges[279][299].
Architecture:
from langchain.memory import ConversationSummaryBufferMemory
memory = ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=650 # Threshold for summarization
)
# Behavior:
# - Recent messages (< 650 tokens): Stored verbatim
# - Older messages (> 650 tokens): Summarized
How it works:
Turns 1-5 (400 tokens total):
Storage: Full buffer (verbatim messages)
Turn 6 pushes total to 720 tokens (> 650 limit):
1. Summarize turns 1-3 → "Josh introduced himself and asked about memory types"
2. Keep turns 4-6 verbatim
3. New context: [summary] + [turn 4] + [turn 5] + [turn 6]
Tokens: 200 (summary) + 150 (turn 4) + 150 (turn 5) + 150 (turn 6) = 650
Dynamic transition: As conversation grows, more turns get summarized. Recent context always preserved.
Pros:
- ✅ Best of both worlds (detail + context)
- ✅ Handles short and long conversations efficiently
- ✅ Recent messages retain full detail (critical for immediate follow-ups)
- ✅ Historical context maintained via summary
- ✅ Adaptive (summarization triggers only when needed)
Cons:
- ⌠More complex implementation (two storage mechanisms)
- ⌠Still requires summarization LLM (cost)
- ⌠Tuning
max_token_limitrequires experimentation - ⌠Latency when summarization triggers
Use cases:
- General-purpose conversational AI (production default)
- Mixed interaction lengths (some short, some long)
- Customer support with varied ticket complexity
- Production chatbots where conversation length is unpredictable
Tuning recommendations:
max_token_limit=400: Aggressive summarization (cost-optimized)max_token_limit=1000: Balanced (most common)max_token_limit=2000: Conservative (detail-preserved)
5. ConversationEntityMemory: The Knowledge Graph Builder
Philosophy: Extract and track facts about specific entities (people, companies, concepts) mentioned in conversation[271][273].
Architecture:
from langchain.memory import ConversationEntityMemory
memory = ConversationEntityMemory(llm=llm)
# LLM extracts entities and builds knowledge base
How it works:
# Turn 1
Input: "Deven & Sam are working on a hackathon project"
Extracted entities:
{
"Deven": "Deven is working on a hackathon project with Sam.",
"Sam": "Sam is working on a hackathon project with Deven."
}
# Turn 2
Input: "They are adding memory structures to LangChain"
Updated entities:
{
"Deven": "Deven is working on a hackathton project with Sam, adding
memory structures to LangChain.",
"Sam": "Sam is working on a hackathon project with Deven, adding
memory structures to LangChain.",
"LangChain": "LangChain is a framework that Deven and Sam are adding
memory structures to."
}
# Turn 3
Input: "What do you know about Deven?"
Retrieved context:
{
"Deven": "Deven is working on a hackathon project with Sam, adding
memory structures to LangChain. Deven suggested using a
key-value store."
}
Response uses ONLY Deven-specific facts (Sam, LangChain context excluded unless relevant)
Entity extraction process:
- LLM reads user input
- Identifies named entities (NER)
- Extracts facts about each entity
- Updates entity knowledge base (ADD/UPDATE/MERGE)
Storage:
memory.entity_store.store = {
"Deven": "working on hackathon, adding memory to LangChain, suggested key-value store",
"Sam": "working on hackathon with Deven, adding memory to LangChain, founded Daimon company",
"LangChain": "framework for LLM applications, Deven & Sam contributing memory features"
}
Retrieval: When user mentions "Deven" or asks about him, only Deven-related facts are loaded into context (not Sam, unless they're both relevant).
Pros:
- ✅ Focused context retrieval (only relevant entities)
- ✅ Scales better than full buffer (selective loading)
- ✅ Builds structured knowledge graph over time
- ✅ Reduces token waste (excludes irrelevant entity info)
Cons:
- ⌠Requires LLM calls for entity extraction (cost, latency)
- ⌠Misses non-entity information (abstract concepts, preferences)
- ⌠Struggles with ambiguous references ("he," "it," "the company")
- ⌠Over-segmentation (separates related information by entity)
Use cases:
- CRM integration: Track customer names, companies, titles, preferences
- Research assistants: Track paper authors, institutions, key concepts
- Meeting notes: Who said what, action items per person
- Sales conversations: Track stakeholders, decision-makers, budgets
Comparison to BufferMemory:
20-turn conversation mentioning 5 entities:
- BufferMemory: ~3,000 tokens (entire conversation)
- EntityMemory: ~800 tokens (only relevant entity facts for current query)
Savings: 73% token reduction (when query is entity-specific)
6. VectorStoreRetrieverMemory: The Semantic Search Engine
Philosophy: Use vector embeddings for semantic similarity search across conversation history[283][285][288][290].
Architecture:
from langchain.memory import VectorStoreRetrieverMemory
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
# 1. Initialize embeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 2. Create vector store
vectorstore = FAISS.from_texts(
texts=["_initial_"], # Placeholder
embedding=embeddings
)
# 3. Create retriever (fetch top K similar exchanges)
retriever = vectorstore.as_retriever(search_kwargs=dict(k=2))
# 4. Initialize memory
memory = VectorStoreRetrieverMemory(
retriever=retriever,
memory_key="history"
)
How it works:
- Storage phase: Each conversation exchange → embedding → stored in vector database
- Retrieval phase: User query → embedding → cosine similarity search → top-K results
- Context injection: Retrieved exchanges fed to LLM as "relevant history"
Example:
# Turn 1
memory.save_context(
{"input": "My favorite color is blue"},
{"output": "That's nice! Blue is calming."}
)
# Stored as: "Human: My favorite color is blue\nAI: That's nice! Blue is calming."
# Embedding: [0.23, -0.15, 0.89, ..., 0.34] (1536 dimensions)
# Turn 15
memory.save_context(
{"input": "I prefer modern minimalist design"},
{"output": "Great taste! Clean lines and simplicity."}
)
# Turn 30
Query: "What colors should I use for my website?"
# Retrieval process:
1. Query embedding: [0.21, -0.13, 0.91, ..., 0.30]
2. Similarity search finds Turn 1 (color preference: blue)
3. Retrieved context: "Human: My favorite color is blue..."
4. LLM response: "Based on your preference for blue, consider a palette with
navy blue (#001f3f) for headers..."
Why semantic search wins:
- Query: "What colors should I use?" doesn't contain the word "blue"
- Keyword search fails
- Semantic embedding captures intent: asking about colors → retrieves color preference
Supported vector stores[284]:
- Pinecone: Managed, scalable, production-grade
- Weaviate: Open-source, self-hosted, schema-based
- Chroma: Lightweight, embedded, developer-friendly
- FAISS: High-performance, local, no server required
- Qdrant: Rust-based, fast, filtering support
- Milvus: Distributed, enterprise-scale
Pros:
- ✅ Semantic search (not keyword matching)
- ✅ Scales to very long conversations (millions of messages)
- ✅ Cross-session memory (persists beyond runtime)
- ✅ Retrieves only relevant exchanges (efficient)
- ✅ Works with existing vector DB infrastructure (RAG + memory hybrid)
Cons:
- ⌠Requires vector database setup (infrastructure complexity)
- ⌠Embedding costs ($0.10 per 1M tokens for OpenAI text-embedding-3-small)
- ⌠Storage costs (Pinecone: $70/mo for 10M vectors serverless tier)
- ⌠Quality depends on embedding model (weak embeddings = poor retrieval)
- ⌠Can retrieve irrelevant context if query is ambiguous
Cost example:
1,000 users, 100 conversations each, 20 turns per conversation
= 2,000,000 exchanges
Embedding generation:
- Avg 100 tokens/exchange = 200M tokens
- OpenAI text-embedding-3-small: $0.02 per 1M tokens
- Cost: $4 one-time
Pinecone storage:
- 2M vectors @ $0.10 per 1K vectors/month = $200/month
Total first year: $4 + ($200 × 12) = $2,404
Alternative (FAISS, self-hosted):
- Embedding: $4
- Storage: ~10GB SSD space (free or $1/mo on cloud)
- Total: $4 + $12 = $16/year
Savings with self-hosted: 99.3% ($2,388/year)
Use cases:
- Long-term customer relationships (months/years of conversation history)
- Personalized recommendations (recall past preferences across sessions)
- Support ticket systems (find similar past issues)
- Knowledge base + conversation hybrid (RAG memory for documentation + chat history)
- Research assistants (remember past papers discussed, even months ago)
Architecture Comparison: memU vs LangChain
| Dimension | memU | LangChain Memory |
|---|---|---|
| Philosophy | Autonomous, agent-controlled | Developer-controlled, explicit configuration |
| Storage Format | Markdown files (human-readable) | Strings, lists, dicts, embeddings |
| Organization | Self-organizing (agent decides) | Manual (developer chooses memory type) |
| Multimodal | Native (text, image, audio, video) | Text-only (requires custom preprocessing) |
| Retrieval | Dual-mode (LLM semantic + vector) | Type-dependent (buffer, summary, vector, entity) |
| Accuracy | 92.09% (Locomo benchmark) | Varies by type (not benchmarked directly) |
| Cost | 90% reduction vs traditional | Varies widely (buffer: high, summary: medium, vector: medium) |
| Latency | ~50ms retrieval | Buffer: low (<10ms), Summary: high (500ms LLM call), Vector: medium (20-200ms) |
| Scalability | Millions of items (file-based + vector) | Depends on type (buffer: poor, vector: excellent) |
| Traceability | Full (Resource → Item → Category) | Partial (buffer: yes, summary: no, vector: yes) |
| Cross-Session | Yes (persistent files) | Depends (buffer/summary: no unless persisted, vector: yes) |
| Setup Complexity | Medium (install memU, configure LLM) | Low (5-line setup) to Medium (vector DB infrastructure) |
| Learning Curve | Medium (understand 3-layer architecture) | Low (buffer/window) to High (vector, entity) |
| Framework Lock-in | Standalone (works with any LLM) | LangChain ecosystem |
Production Deployment Guide
Cost Analysis: Database Pricing
Memory systems require persistent storage. Here's 2026 pricing for common backends[291][293][295]:
MongoDB Atlas (Document Database)
Use case: Storing memU's Markdown category files, LangChain buffer/summary memories
| Tier | Storage | RAM | vCPUs | Price | Use Case |
|---|---|---|---|---|---|
| M0 | 512 MB | Shared | Shared | Free forever | Prototyping, personal projects |
| M2 | 2 GB | Shared | Shared | $9/mo | Small workloads, testing |
| M5 | 5 GB | Shared | Shared | $25/mo | Entry-level production (<1K users) |
| M10 | 10 GB | 2 GB | 2 vCPUs | $0.08/hr (~$58/mo) | Production (1K-10K users) |
| M30 | 40 GB | 8 GB | 2 vCPUs | $0.54/hr (~$389/mo) | Medium production (10K-100K users) |
| M50 | 160 GB | 32 GB | 8 vCPUs | $2.00/hr (~$1,440/mo) | Large production (100K+ users) |
Serverless pricing (auto-scales):
- Read operations: $0.10 per million RPUs (first 50M/day)
- Write operations: $1.00 per million WPUs
- Storage: $0.30/GB-month
- Backup: $0.20/GB-month
Recommendation for memU:
- Development: M0 (free)
- Small production (1K-5K users): M5 ($25/mo)
- Medium production (10K-50K users): M10 ($58/mo)
- Large production (50K-500K users): M30 ($389/mo)
Redis (In-Memory Cache)
Use case: Short-term memory (working context), LangChain BufferWindowMemory, session state
| Tier | Description | Price | Use Case |
|---|---|---|---|
| Open-source (self-hosted) | DigitalOcean 4GB RAM droplet | $24/mo | Small-medium workloads (<50K req/sec) |
| Redis Cloud Essentials | Basic managed service | $0.014/hr minimum ($200/mo) | Production with SLA |
| Redis Cloud Pro | Dedicated, multi-region, auto-tiering | Custom pricing | Enterprise (99.999% uptime) |
Recommendation for short-term memory:
- Development: Self-hosted Redis on $24/mo droplet
- Production (<100K users): Redis Cloud Essentials ($200/mo)
- Enterprise (1M+ users): Redis Cloud Pro (custom pricing)
Pinecone (Vector Database)
Use case: LangChain VectorStoreRetrieverMemory, memU vector search
| Tier | Capacity | Price | Use Case |
|---|---|---|---|
| Serverless (free tier) | 2M vectors, 1 pod | Free | Development, prototyping |
| Serverless (paid) | Pay per read/write | $0.10 per 1K vectors/mo | Small-medium production |
| Pod-based | Dedicated pods | $70/mo per p1 pod (1M vectors) | Large production, low-latency requirements |
Recommendation for vector memory:
- Development: Serverless free tier (2M vectors)
- Small production (10M vectors): Serverless paid ($100/mo)
- Medium production (100M vectors): Pod-based ($700/mo, 10 pods)
- Large production (1B+ vectors): Pod-based + sharding ($7K+/mo)
Architecture Patterns: Hybrid Memory Systems
Most production systems in 2026 use hybrid architectures combining multiple memory types[297][300][303]:
Pattern 1: Three-Tier Memory Stack (Standard)
# Tier 1: Short-term (working context)
redis_cache = Redis(host="localhost", port=6379, db=0)
short_term_memory = ConversationBufferWindowMemory(k=5)
# Tier 2: Long-term (persistent storage)
vectorstore = Pinecone(index_name="user_memories")
long_term_memory = VectorStoreRetrieverMemory(
retriever=vectorstore.as_retriever(search_kwargs=dict(k=10))
)
# Tier 3: Semantic (entity knowledge)
entity_memory = ConversationEntityMemory(llm=llm)
# Retrieval strategy:
def get_context(user_id, query):
# 1. Check short-term (last 5 turns)
recent = short_term_memory.load_memory_variables({})["history"]
# 2. Retrieve long-term (semantic search)
historical = long_term_memory.load_memory_variables({"input": query})["history"]
# 3. Get entity facts
entities = entity_memory.load_memory_variables({"input": query})["entities"]
# 4. Combine contexts
full_context = f"{recent}\n\nRelevant history:\n{historical}\n\nEntities:\n{entities}"
return full_context
Token budget:
- Short-term: ~800 tokens (5 recent exchanges)
- Long-term: ~1,500 tokens (10 retrieved exchanges)
- Entity: ~300 tokens (5 entities × 60 tokens each)
- Total: ~2,600 tokens (fits comfortably in 128K context window)
Pattern 2: memU + LangChain Hybrid (Best of Both Worlds)
# Use memU for autonomous long-term memory
from memu import MemoryService
memu = MemoryService(
storage_path="/data/memories",
llm=llm,
retrieval_mode="dual" # LLM-based + vector
)
# Use LangChain for structured short-term memory
short_term = ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=1000
)
# Agent workflow:
def chat(user_id, message):
# 1. Load short-term context (recent conversation)
recent_context = short_term.load_memory_variables({})["history"]
# 2. Query memU for relevant long-term memories
memories = memu.retrieve(
user_id=user_id,
query=message,
top_k=5
)
# 3. Combine contexts
full_context = f"""
Recent conversation:
{recent_context}
Relevant memories from past interactions:
{memories}
Current message: {message}
"""
# 4. Generate response
response = llm.invoke(full_context)
# 5. Update memories
short_term.save_context({"input": message}, {"output": response})
memu.save(user_id=user_id, resource=message, response=response)
return response
Advantages:
- memU: Handles multimodal inputs, autonomous organization, high accuracy
- LangChain: Structured short-term management, battle-tested, flexible
- Combined: Best accuracy (memU) + best flexibility (LangChain)
Pattern 3: Semantic + Episodic + Procedural (Enterprise)
# Semantic memory (facts, knowledge)
semantic_store = Chroma(collection_name="semantic_facts")
# Episodic memory (time-bound events)
episodic_store = MongoDB(collection="episodic_events")
# Procedural memory (workflows, how-tos)
procedural_store = Neo4j(graph="workflows")
# Retrieval strategy:
def retrieve_context(user_id, query, task_type):
if task_type == "question_answering":
# Use semantic memory (facts)
return semantic_store.similarity_search(query, k=10)
elif task_type == "conversation":
# Use episodic memory (past exchanges)
return episodic_store.find({"user_id": user_id}).sort("timestamp", -1).limit(10)
elif task_type == "task_execution":
# Use procedural memory (workflows)
return procedural_store.query(f"MATCH (n:Workflow) WHERE n.task = '{task_type}' RETURN n")
Use cases:
- Enterprise AI assistants (sales, support, DevOps)
- Multi-domain agents (legal, medical, financial)
- Autonomous task execution (RPA, workflow automation)
Token Optimization Strategies
Token consumption is the primary cost driver. Here's how to optimize[296][299][302]:
Strategy 1: Trim Messages (Pre-Processing)
from langchain.memory import trim_messages
# Keep last 10 messages only
trimmed = trim_messages(
messages,
max_tokens=2000,
strategy="last", # or "first", "relevant"
)
Savings: 60-80% for long conversations
Strategy 2: Summarize Periodically (Batch Compression)
# Every 20 turns, summarize and reset
if turn_count % 20 == 0:
summary = llm.invoke(f"Summarize this conversation:\n{conversation_history}")
conversation_history = f"Previous conversation summary: {summary}"
Savings: 70-90% for very long conversations (100+ turns)
Strategy 3: Prompt Caching (Redis Layer)
import redis
cache = redis.Redis(host="localhost", port=6379, db=0)
def get_llm_response(prompt):
# Check cache first
cached = cache.get(prompt)
if cached:
return cached.decode("utf-8")
# Cache miss: call LLM
response = llm.invoke(prompt)
cache.setex(prompt, 3600, response) # TTL: 1 hour
return response
Savings: 90-95% for repeated queries (FAQ, common questions)
Strategy 4: MapReduce for Long Documents (Parallel Processing)
from langchain.chains import MapReduceDocumentsChain
# Split long conversation into chunks
chunks = split_conversation(conversation, chunk_size=2000)
# Parallel summarization
summaries = [llm.invoke(f"Summarize: {chunk}") for chunk in chunks]
# Final reduction
final_summary = llm.invoke(f"Combine these summaries: {summaries}")
Savings: 40-60% token reduction, faster processing (parallel)
Strategy 5: Model Selection (Cheap Models for Simple Tasks)
# Use gpt-3.5-turbo for summarization, gpt-4 for reasoning
summary_llm = OpenAI(model="gpt-3.5-turbo") # $0.50/M tokens
reasoning_llm = OpenAI(model="gpt-4o") # $5.00/M tokens
memory = ConversationSummaryMemory(llm=summary_llm) # Cheap model for memory management
agent = Agent(llm=reasoning_llm) # Expensive model for user-facing responses
Savings: 70-90% on memory operations
Production Checklist
Before deploying memory-enabled AI agents[300]:
✅ Architecture:
- Choose memory type(s) based on conversation length and requirements
- Implement multi-tier architecture (short-term + long-term + entity)
- Set up database infrastructure (MongoDB, Redis, Pinecone)
- Design retrieval strategy (k values, similarity thresholds)
✅ Performance:
- Benchmark token consumption across memory types
- Implement prompt caching for repeated queries
- Set up monitoring (token usage, latency, accuracy)
- Load test memory retrieval at expected scale
✅ Cost:
- Estimate monthly costs (database, embeddings, LLM calls)
- Implement budget alerts (token limits, database caps)
- Optimize with cheaper models for memory operations
- Plan for scaling (cost per user, per conversation)
✅ Data Management:
- Implement TTL (time-to-live) for short-term memories
- Set up data retention policies (GDPR, privacy compliance)
- Backup strategy for long-term memories
- User data deletion workflow (right to be forgotten)
✅ Monitoring:
- Track memory retrieval accuracy (relevance scoring)
- Monitor token consumption trends
- Alert on memory retrieval failures
- Dashboard for memory health (size, latency, hit rate)
Decision Framework: Choosing Your Memory System
Flowchart: Which Memory Type?
START
├─ Conversation length?
│ ├─ <10 turns → ConversationBufferMemory
│ ├─ 10-50 turns → ConversationSummaryBufferMemory
│ └─ >50 turns → Continue...
│
├─ Multimodal inputs (images/audio)?
│ ├─ Yes → memU
│ └─ No → Continue...
│
├─ Need autonomous organization?
│ ├─ Yes → memU
│ └─ No → Continue...
│
├─ Semantic search required?
│ ├─ Yes → VectorStoreRetrieverMemory or memU
│ └─ No → Continue...
│
├─ Entity tracking critical?
│ ├─ Yes → ConversationEntityMemory
│ └─ No → Continue...
│
├─ Token budget?
│ ├─ Tight → ConversationBufferWindowMemory
│ ├─ Medium → ConversationSummaryMemory
│ └─ Generous → ConversationBufferMemory
│
└─ Cross-session persistence?
├─ Yes → VectorStoreRetrieverMemory or memU
└─ No → Any in-memory type (Buffer, Summary, Window)
Use Case Matrix
| Use Case | Conversation Length | Multimodal | Autonomy | Cost | Recommendation |
|---|---|---|---|---|---|
| Customer support chatbot | Short (5-10 turns) | No | Low | Low | ConversationBufferWindowMemory (k=5) |
| AI therapy/coaching | Very long (50+ turns) | No | Medium | Medium | ConversationSummaryBufferMemory |
| Personal AI companion | Infinite (weeks/months) | Yes | High | Medium | memU |
| Sales CRM assistant | Medium (20-30 turns) | No | Low | Medium | ConversationEntityMemory (track contacts) |
| Research assistant | Long (30+ turns) | Yes | Medium | High | memU or VectorStoreRetrieverMemory |
| Meeting notes bot | Medium (15-25 turns) | Yes | Medium | Medium | ConversationEntityMemory (who said what) |
| Customer support (returning users) | Cross-session | No | Low | Medium | VectorStoreRetrieverMemory |
| DevOps AI agent | Variable | Yes | High | Medium | memU (multimodal logs, autonomous) |
| FAQ chatbot | Very short (1-3 turns) | No | Low | Very low | ConversationBufferMemory + caching |
| Legal document assistant | Long (40+ turns) | No | Low | High | ConversationSummaryMemory (detail preservation) |
Hybrid Recommendations
Best for most production use cases:
Short-term: ConversationSummaryBufferMemory (recent detail + summary)
Long-term: VectorStoreRetrieverMemory (cross-session, semantic search)
Entity tracking: ConversationEntityMemory (structured facts)
Best for AI companions:
Long-term: memU (multimodal, autonomous, high accuracy)
Short-term: ConversationBufferWindowMemory (immediate context)
Best for enterprise:
Short-term: Redis-cached ConversationSummaryBufferMemory
Long-term: Pinecone VectorStoreRetrieverMemory
Entity: MongoDB ConversationEntityMemory
Procedural: Neo4j workflow graphs
Advanced Topics
Mem0: The Production-Ready Alternative
If memU's autonomous approach feels too opaque or you need proven enterprise reliability, Mem0 offers a middle ground[263][275][284][286][289]:
Performance:
- 66.9% accuracy on Locomo (vs OpenAI: 52.9%) = 26% relative uplift
- 91% lower p95 latency (1.44s vs OpenAI)
- 90% token savings
- Median search: 0.20s (p95: 0.15s)
Architecture:
- Extractor: Identifies key information from conversations
- Updater: Compares new info with existing memories (ADD/UPDATE/DELETE/NOOP)
- Retriever: Fetches relevant memories via vector similarity
- Memory Store: Pluggable backend (Qdrant, Chroma, Pinecone, FAISS)
Mem0-Graph (advanced variant):
- Entities as nodes (with types, embeddings, metadata)
- Relationships as edges (source, relation, destination)
- Graph traversal + semantic triplet matching
- 68.4% accuracy (vs base Mem0: 66.9%)
- Higher latency (0.66s median) but better for complex relational queries
When to use Mem0:
- Enterprise production (proven at scale)
- Need relationship tracking (Mem0-Graph for entity connections)
- Want both vector + graph capabilities
- Require temporal reasoning (track preference changes over time)
- Multi-user hierarchical memory (user/session/agent levels)
Future of AI Memory: 2026 and Beyond
Trend 1: Memory > Context [260][297][303] Long-term memory is becoming more valuable than large context windows. GPT-4's 128K context enables document processing, but persistent memory enables genuine learning.
Trend 2: Multi-Tiered Standard Short-term + long-term + feedback loops are now table stakes for production agents[297][303].
Trend 3: Graph Memory Rising Entity relationships (graph-based) outperforming flat vector search for complex reasoning[263][289].
Trend 4: MCP Adoption (Memory Communication Protocol)[297] Standardizing memory interactions across frameworks:
from autogen_tools import MCP
protocol = MCP(protocolName="memory-sync")
Trend 5: Agentic Memory > RAG 2026 prediction: Agentic memory will surpass RAG in usage for adaptive AI workflows[260][303].
Trend 6: "Year of AI Memory"[260] Memory infrastructure becoming table stakes, not a competitive advantage. The shift from "prompt engineering" to "memory architecture"[303].
Conclusion: Building Agents That Truly Remember
The difference between a chatbot and an AI companion is memory. Not just storing conversations, but understanding, organizing, and adapting based on accumulated knowledge.
Key takeaways:
-
memU wins for autonomous AI companions: 92% accuracy, 90% cost reduction, multimodal support, self-organizing memory[266][268][280].
-
LangChain wins for structured flexibility: Six memory types, battle-tested in production, extensive ecosystem integration[257][265].
-
Hybrid approaches dominate production: Combine short-term (BufferWindowMemory), long-term (VectorStoreRetrieverMemory), and entity tracking (EntityMemory) for comprehensive coverage[297][300].
-
Memory architecture matters more than model size: A GPT-3.5 with excellent memory outperforms GPT-4 without memory for personalized tasks.
-
2026 is the year of memory: From "prompt engineering" to "memory architecture" as the defining competitive advantage[303].
Action plan:
- Prototype: Start with
ConversationBufferMemory(5 lines) - Optimize: Switch to
ConversationSummaryBufferMemoryfor production - Scale: Add
VectorStoreRetrieverMemoryfor cross-session persistence - Advanced: Implement memU for multimodal autonomous agents
- Enterprise: Deploy hybrid architecture with monitoring, cost controls, compliance
The agents that remember, learn, and adapt will define the next generation of AI. The architecture is here. The tools are production-ready. Now it's time to build.
Further Resources
memU:
- GitHub: https://github.com/NevaMind-AI/memU
- Documentation: https://memu.pro/docs
- Benchmark: https://memu.pro/benchmark (92% Locomo accuracy)
- Podcast deep dive: https://www.youtube.com/watch?v=fRDNi8ehTns[157]
LangChain Memory:
- Official docs: https://python.langchain.com/docs/modules/memory/
- Memory types guide: https://www.projectpro.io/article/langchain-memory/1161[257]
- Conversational memory tutorial: https://www.pinecone.io/learn/series/langchain/langchain-conversational-memory/[299]
- Aurelio AI memory guide: https://www.aurelio.ai/learn/langchain-conversational-memory[276]
Mem0 (Alternative):
- Platform: https://mem0.ai
- Research paper: https://mem0.ai/research (26% accuracy boost)[275]
- Graph memory docs: https://docs.mem0.ai/platform/features/graph-memory[289]
Advanced Reading:
- A-Mem: Agentic Memory for LLM Agents (arXiv): https://arxiv.org/html/2502.12110v11[277]
- Cortex Memory Architecture (Rust implementation): https://dev.to/sopaco/ai-agent-memory-management-system-architecture-design-evolution-from-stateless-to-intelligent-2c4h[300]
- Sparkco AI Memory Systems Guide: https://sparkco.ai/blog/ai-agent-memory-systems-architecture-and-innovations[297]
Last updated: January 28, 2026. Benchmarks, pricing, and features subject to change. All data verified against official sources and production deployments.