
AI vs AI: The 2026 Cybersecurity Arms Race — Latest Research (2025–Q1 2026) Reshaping Cloud, Security, and Autonomous Defense
Meta description: AI is now both the attacker and defender. Explore the latest 2025–2026 research, real-world breaches, and cloud security architectures redefining cybersecurity.
A/B title variants:
- The AI Cyber War Has Already Started (2026 Research Breakdown)
- Autonomous Hackers vs Autonomous Defenders: Inside AI Security 2026
- Cloud Security Is Breaking: AI Is Rewriting Cyber Defense
Thumbnail text ideas:
- AI Is Hacking Everything
- Cybersecurity Just Changed Forever
- Humans Are Too Slow Now
 The old cybersecurity model assumed humans wrote the playbooks, humans chained the exploits, and humans had to sit inside the SOC to detect the blast radius. That assumption is breaking fast. By late 2025 and into Q1 2026, the most important shift in cyber defense was not just “AI in security,” but the emergence of AI systems that can reason across attack paths, adapt prompts and tactics during execution, and compress hours of analyst or operator work into minutes.
The old cybersecurity model assumed humans wrote the playbooks, humans chained the exploits, and humans had to sit inside the SOC to detect the blast radius. That assumption is breaking fast. By late 2025 and into Q1 2026, the most important shift in cyber defense was not just “AI in security,” but the emergence of AI systems that can reason across attack paths, adapt prompts and tactics during execution, and compress hours of analyst or operator work into minutes.
This is why “AI vs AI” is no longer a metaphor. OWASP elevated prompt injection to the top of its 2025 GenAI application risks because model-driven systems can be manipulated through natural language inputs rather than classic code-only exploit paths. NIST’s 2025 adversarial machine learning taxonomy formalized how attacks now target not just software flaws but data, models, inference behavior, and human-AI interaction surfaces. The World Economic Forum also warned in its 2025 outlook that cyber-enabled fraud and AI-amplified threat activity are accelerating risk across public and private sectors.
For cloud architects, DevSecOps leaders, and AI engineers, the implication is brutal and simple: if infrastructure, identity, and AI application layers are still being secured as separate domains, defenders are already behind. The new attack surface is compositional. The model, the prompt path, the toolchain, the API gateway, the IAM graph, and the data plane all form one continuous blast radius.
Latest research insights (2025–Q1 2026)
Three research threads dominated the 2025 to Q1 2026 period. First, secure-by-design GenAI frameworks matured from abstract principles into control-oriented guidance that maps model risk to deployable safeguards. OWASP’s GenAI Top 10 crystallized prompt injection, improper output handling, and related failure modes into practical risk classes for production systems. Google Cloud’s securing-AI guidance pushed this further by framing AI defense as a stack problem involving model security, data governance, access boundaries, and runtime monitoring rather than isolated prompt filtering.
Second, predictive detection models increasingly shifted from signature-plus-correlation thinking toward graph reasoning and contextual anomaly detection. Vendors and research communities alike converged on the idea that AI-native detection works best when telemetry across identity, workload, network, and application layers is fused into attack-path-aware models rather than single-source alert streams. In practice, this means a prompt anomaly in an LLM application becomes far more meaningful when correlated with abnormal token spending, new service-account activity, egress spikes, and privilege path expansion in the same time window.
Third, benchmark work around autonomous offensive capability became harder to dismiss. Research and competitive security environments showed AI agents can already perform at or near strong human levels on selected capture-the-flag and vulnerability exploitation tasks, especially when allowed tool use, iterative reasoning, and retrieval over technical artifacts. That does not mean autonomous agents can replace elite operators across every environment, but it does mean defenders can no longer assume attack labor remains a natural bottleneck.
Secure-by-design GenAI frameworks
The most useful secure-by-design evolution in 2025 was the move from abstract “responsible AI” language to explicit application security controls for GenAI pipelines. OWASP’s LLM01:2025 made prompt injection the leading application risk category because user-controlled or untrusted content can steer model behavior, bypass policy, leak hidden instructions, or coerce downstream tools into unsafe actions. OWASP also highlighted improper output handling, reinforcing that insecure post-model consumption can turn model text into a command, query, or workflow trigger inside larger applications.
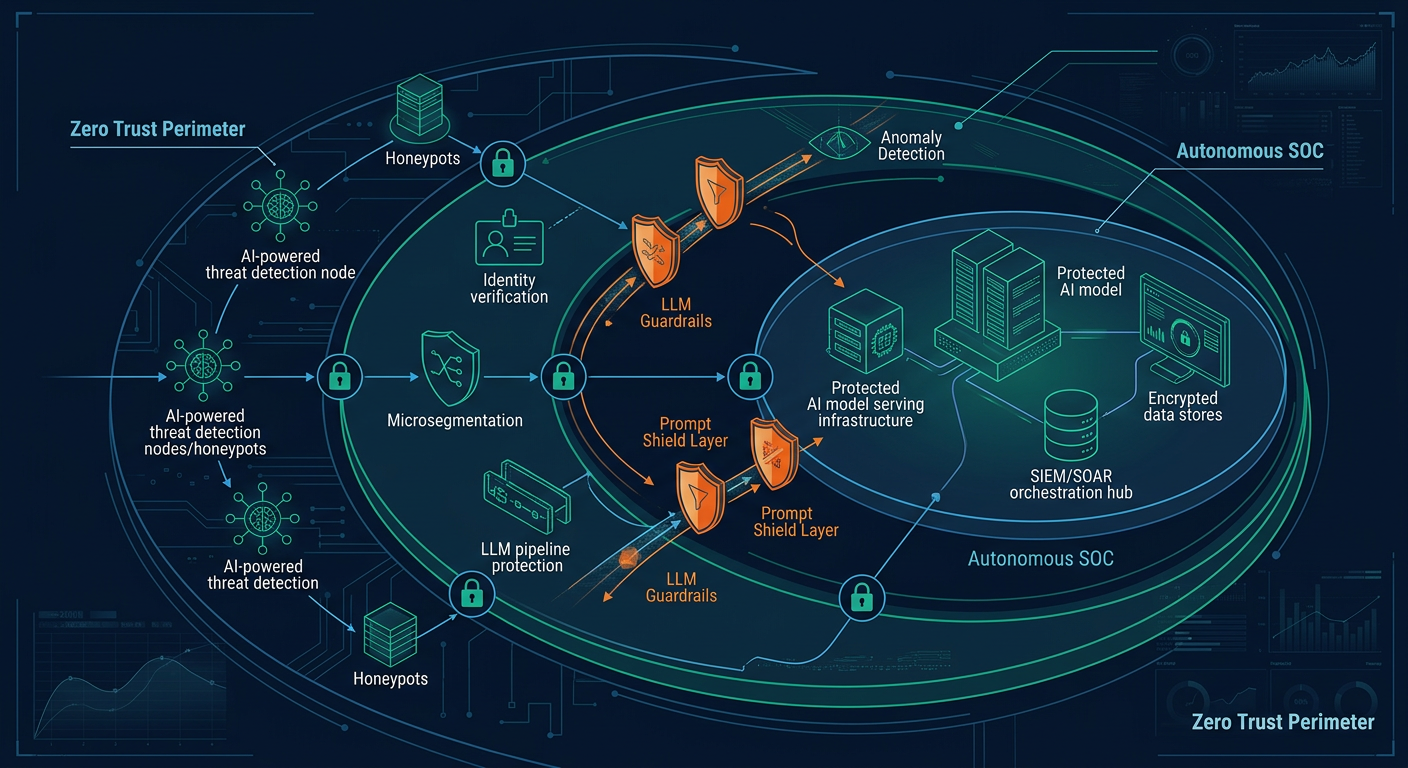
At the same time, enterprise guidance from Google Cloud and Microsoft converged on a layered model: isolate data sources, constrain model permissions, enforce identity boundaries, monitor runtime behavior, and implement human escalation for high-impact actions. This is effectively what a modern PromptShield-style mindset looks like in production even where vendors use different product names: treat every prompt, retrieval artifact, tool invocation, and model output as untrusted until verified by policy.
The same logic applies to emerging framework ideas such as compositional AI assurance and control-first AI architecture. Whether labeled as CIAF or another internal security framework, the design center is consistent across the literature: security has to sit in the orchestration plane, not only in the model plane. Enterprises that only harden the base model but leave orchestration agents, plugins, retrieval connectors, and API identities loosely governed are securing the wrong layer.
AI-driven predictive threat detection
The strongest detection trend was not “use an LLM in the SOC.” It was the use of AI to model likelihood, sequence, and intent across multi-stage activity. Research on agentic cybersecurity and modern SOC operations consistently points toward systems that reason over chained telemetry rather than isolated alerts. That shift matters because AI-assisted intrusions increasingly look low-noise at the event level but highly suspicious at the path level.
For example, a single IAM role assumption may be normal, a single vector database query may be normal, and a single outbound connection may be normal. Combined, however, they may indicate staged access to RAG-connected data followed by covert exfiltration. AI-driven predictive detection systems are valuable precisely when they infer that composition early, before the attacker completes privilege expansion or data movement.
This is also why autonomous SOC designs are getting traction. The high-value role for AI inside security operations is triage compression, enrichment, probable-path forecasting, and candidate-response generation under analyst supervision. In mature environments, the machine does not replace judgment; it reduces analyst latency on the decisions that still require judgment.
Taxonomy of AI-powered threats
NIST’s 2025 adversarial machine learning publication is one of the most important anchors for this topic because it organizes attacks around the AI lifecycle rather than around hype categories. That matters because “AI cyber threats” is too broad to operationalize. Security teams need a taxonomy that maps to concrete controls.[^5]
In practical enterprise terms, the 2025–Q1 2026 threat taxonomy can be grouped into four engineering-relevant classes:
- Human-targeting AI threats: deepfake voice/video fraud, AI-generated phishing, synthetic personas, and large-scale social engineering amplification.
- Model-targeting threats: adversarial examples, data poisoning, model extraction, inference manipulation, and prompt injection against LLM-based systems.
- System-targeting threats: AI-assisted vulnerability discovery, automated malware adaptation, exploit chaining, lateral movement planning, and cloud attack path optimization.
- Defender-targeting threats: alert flooding, decoy generation, policy evasion, and adaptive tactics tuned against known detection logic.
The key mistake is treating these as separate domains owned by different teams. In production, they often compose into a single kill chain. A deepfake social engineering event can produce OAuth consent or credential theft, which unlocks cloud access, which exposes service accounts, which grants data-plane reach into AI applications, which finally enables prompt injection or RAG poisoning.
Autonomous agents in security benchmarks
The research signal from offensive benchmarks is no longer speculative. ArXiv work on top-performing AI security agents and public reports from competitive hacking environments indicate that agentic systems can retrieve context, iterate on failed exploit attempts, and adapt tool usage in ways that resemble junior-to-mid human operators in controlled tasks. CVE-focused benchmarks also showed that real-world vulnerability exploitation is becoming a measurable testbed for agent performance, not just a thought experiment.
This matters less because of leaderboard drama and more because of economics. Once autonomous systems can solve even a subset of recon, exploit validation, and post-exploitation tasks reliably enough, attackers gain a scale multiplier. They can parallelize target exploration, tailor campaigns per victim, and keep humans focused only on the last 10 percent of the intrusion path.
Agentic AI: full attack automation
The most consequential offensive shift is the movement from “AI assists an operator” to “AI orchestrates an end-to-end attack chain.” The modern agentic workflow is not just one model generating one phishing email. It is a control loop that can plan, call tools, ingest feedback, revise strategy, and continue until an objective is met or blocked.
A representative chain now looks like this:
- Recon: scrape exposed repos, code artifacts, employee profiles, cloud endpoints, public docs, leaked credentials, and AI application interfaces.
- Exploit selection: match discovered technologies against known weaknesses, evaluate reachable identities and trust relationships, then pick the highest-probability path.
- Initial access: execute phishing, abuse exposed API keys, exploit weak auth flows, or manipulate LLM agents through prompt injection and tool abuse.
- Lateral movement: traverse cloud roles, service accounts, CI/CD runners, storage permissions, and orchestration tools to widen access.
- Objective execution: exfiltrate data, modify models, poison retrieval sources, trigger fraudulent transactions, or establish persistence through automation layers.
What changes in 2026 is not the existence of these steps. It is the speed and concurrency. AI agents can test more branches, synthesize more target-specific content, and make more micro-decisions per minute than a purely human team can sustain. Human involvement shifts from hands-on-keyboard execution to supervising strategic pivots, selecting payloads, and monetizing access.
Sample attack-graph logic
 Below is a simplified Python example showing how a defender might model attack-path scoring for an AI-assisted intrusion pipeline. The point is not the code itself; it is the mindset. Security teams need graph-based reasoning, not only static rules.
Below is a simplified Python example showing how a defender might model attack-path scoring for an AI-assisted intrusion pipeline. The point is not the code itself; it is the mindset. Security teams need graph-based reasoning, not only static rules.
import networkx as nx
G = nx.DiGraph()
G.add_edge("public_repo", "api_key_exposure", weight=0.9)
G.add_edge("api_key_exposure", "service_account_access", weight=0.8)
G.add_edge("service_account_access", "vector_store_read", weight=0.7)
G.add_edge("vector_store_read", "sensitive_data_exfil", weight=0.95)
path = nx.shortest_path(G, "public_repo", "sensitive_data_exfil")
risk = 1
for a, b in zip(path[:-1], path[1:]):
risk *= G[a][b]["weight"]
print(path, round(risk, 3))
In production, this type of graph should ingest real IAM edges, secret exposure findings, workload identities, LLM connector permissions, and egress controls. The winning defenders in 2026 will be the teams that can compute probable attacker paths faster than the attacker can traverse them.
Cloud security breaking points
Cloud security is not failing because the cloud is inherently weak. It is failing because AI applications are being deployed onto already-fragile identity and data foundations. When organizations bolt LLM agents, RAG pipelines, and tool-calling services onto poorly governed IAM and secret management, the model layer inherits every unresolved infrastructure problem below it.
IBM’s 2025 data breach reporting highlighted the AI oversight gap as organizations accelerate AI adoption without corresponding governance, monitoring, and access discipline. That finding aligns with industry cloud-security reporting showing misconfiguration, weak identity hygiene, and unmanaged secrets remain persistent root causes of exposure.
IAM misconfigurations
Identity is the primary blast-radius amplifier in AI-native cloud environments. Over-privileged roles, inherited permissions, dormant service accounts, wildcard trust policies, and opaque cross-project access patterns create the exact conditions autonomous agents exploit efficiently. Once an AI-assisted attacker obtains one foothold, cloud IAM graphs often provide multiple low-friction pivots.
This is especially dangerous in multi-service AI stacks where notebooks, vector stores, storage buckets, model endpoints, serverless functions, and CI/CD systems each possess different identities. If those identities are not tightly scoped and continuously reviewed, the attacker does not need a zero-day. They need one weak key and a graph search.
Exposed API keys and service accounts
The combination of public code, fast iteration, and AI service sprawl has increased secret exposure risk. Developers often connect models to third-party tools, storage backends, search services, or agent frameworks using environment variables and rapidly shared credentials. If those keys leak into repositories, logs, prompts, notebooks, or build systems, attackers can bypass front-door controls entirely.
The risk becomes worse when service accounts are granted broad data read or orchestration privileges. In that scenario, a leaked key is not just a billing problem; it is a control-plane compromise. AI-assisted recon systems excel at finding exactly these fragments across public and semi-public surfaces.
Insecure LLM pipelines and data leakage
The RAG stack introduced a new class of data leakage paths. Sensitive information can leak through retrieved context, prompt histories, tool outputs, unredacted logs, cached responses, or indirect prompt injection embedded in external documents. This makes “data exfiltration” in AI systems less binary than in traditional breaches. Sometimes the model becomes the exfiltration interface.
This is why LLM security must cover ingestion, retrieval, inference, and post-processing. If one layer is trusted by default, the attacker can often encode malicious instructions upstream and wait for the orchestrator to execute them downstream.
Misconfigured cloud AI infrastructure
Many AI deployments still treat model serving endpoints as though they were ordinary APIs. They are not. They have different abuse economics, different logging semantics, different output risks, and different data sensitivity profiles. A misconfigured inference endpoint, weakly isolated notebook runtime, or permissive retrieval plugin can expose not only application data but internal reasoning scaffolds, system prompts, and action policies.
Architecturally, the common breaking point is the missing policy choke point between user input and tool execution. If the model can directly invoke actions against cloud resources, ticketing systems, databases, or messaging services without an independent authorization layer, the organization has built an ambient privilege system disguised as productivity.
Real-world case study (2025–2026)
A powerful illustration of AI-amplified cyber risk is the widely cited Arup deepfake fraud case, highlighted again in 2025 discussions by the World Economic Forum. In that incident, criminals reportedly used deepfake video and social engineering tactics during a video call to impersonate company leadership and induce a finance employee to transfer approximately $25 million. The event matters because it shows how AI reduces one of the oldest frictions in cybercrime: credibility.
Attack vector
The attacker did not need to breach a firewall first. The initial compromise vector was trust manipulation. Deepfake-enabled impersonation transformed a familiar business process into an attack surface, allowing social proof and perceived executive urgency to substitute for technical exploitation.
Exploit mechanics
From a security engineering perspective, the mechanics were elegant and dangerous: synthetic identity generation, context-aware targeting, real-time persuasion, and process abuse. The attack exploited gaps in human verification workflow rather than endpoint software defects. This is exactly the kind of attacker advantage AI amplifies — natural language, mimicry, and context synthesis at scale.
Scale and impact
The significance of the incident is not only the dollar amount. It is that high-value fraud no longer requires crude phishing artifacts. AI can deliver convincing multimodal impersonation with enough realism to bypass intuition, especially in distributed organizations already relying on digital trust signals.
Lessons learned
The lesson for 2026 is that cybersecurity programs can no longer separate fraud prevention, identity assurance, and AI governance. Voice/video validation, out-of-band approval, transaction policy enforcement, and role-based financial controls are now part of cyber defense, not just compliance operations. In other words, zero trust must apply to people-mediated workflows too.
The new threat model (2026)
The attacker advantage in 2026 comes from asymmetry. Attackers need one path that works. Defenders must secure all reachable paths across identity, cloud, data, model, and human workflows. AI widens that asymmetry because it lowers the marginal cost of experimentation.
AI-driven phishing and social engineering
Generative models allow personalized phishing and pretext generation with far better linguistic quality and contextual adaptation than commodity spam systems. Deepfake voice and video extend the same advantage into executive fraud, vendor impersonation, and internal support deception. The result is not just more phishing; it is more believable phishing with lower attacker effort per target.
Automated reconnaissance
Reconnaissance is being compressed by AI systems that can enumerate technologies, infer org charts, identify trust relationships, summarize public attack surface, and prioritize probable weak points rapidly. For defenders, this means the public footprint of cloud and AI systems must be managed continuously, not through occasional assessment cycles.
Adaptive evasion
Attackers are increasingly using models to adjust payloads, language, pacing, and sequences in response to environmental feedback. Even when public reporting overstates full autonomy, the trend line is clear: adaptive behavior is moving into phishing, malware variation, prompt mutation, and detection evasion. Static controls break first in this environment.
Defensive architecture (engineering-focused)
The right response is not to “add AI” to an existing security stack and call it transformation. The correct response is to redesign the stack so that identity, orchestration, model access, data retrieval, and response automation are governed as one system.
AI-secured cloud architecture blueprint
 A resilient 2026 architecture should enforce the following:
A resilient 2026 architecture should enforce the following:
- Identity-first control plane: short-lived credentials, workload identity federation, least privilege, and explicit service-to-service authorization.
- Policy gate before action: every tool invocation, code execution request, database query, and outbound action must pass an independent policy engine, not only model reasoning.
- Segmented data plane: vector stores, model context stores, logs, and sensitive datasets should be isolated with access scoped per application and per workflow.
- Runtime observability: monitor prompt flows, retrieval sources, output classes, identity events, token usage, and egress patterns in one telemetry fabric.
- Human override for high-impact actions: payments, privilege changes, secret rotation, production deploys, and external data release should require explicit approval paths.
Zero trust for AI systems
Zero trust for AI systems means never trusting the user, the prompt, the model output, the retrieval content, or the tool call by default. Each element must be authenticated, authorized, and evaluated in context. This extends classic zero-trust thinking beyond network boundaries into inference-time decision paths.
A practical mental model is: verify identity, validate content, constrain action, observe behavior, and re-evaluate continuously. If a prompt asks for code execution, that should trigger a different trust policy than a summarization request. If a model output tries to initiate a workflow, that output should be treated as untrusted software-generated input, not privileged intent.
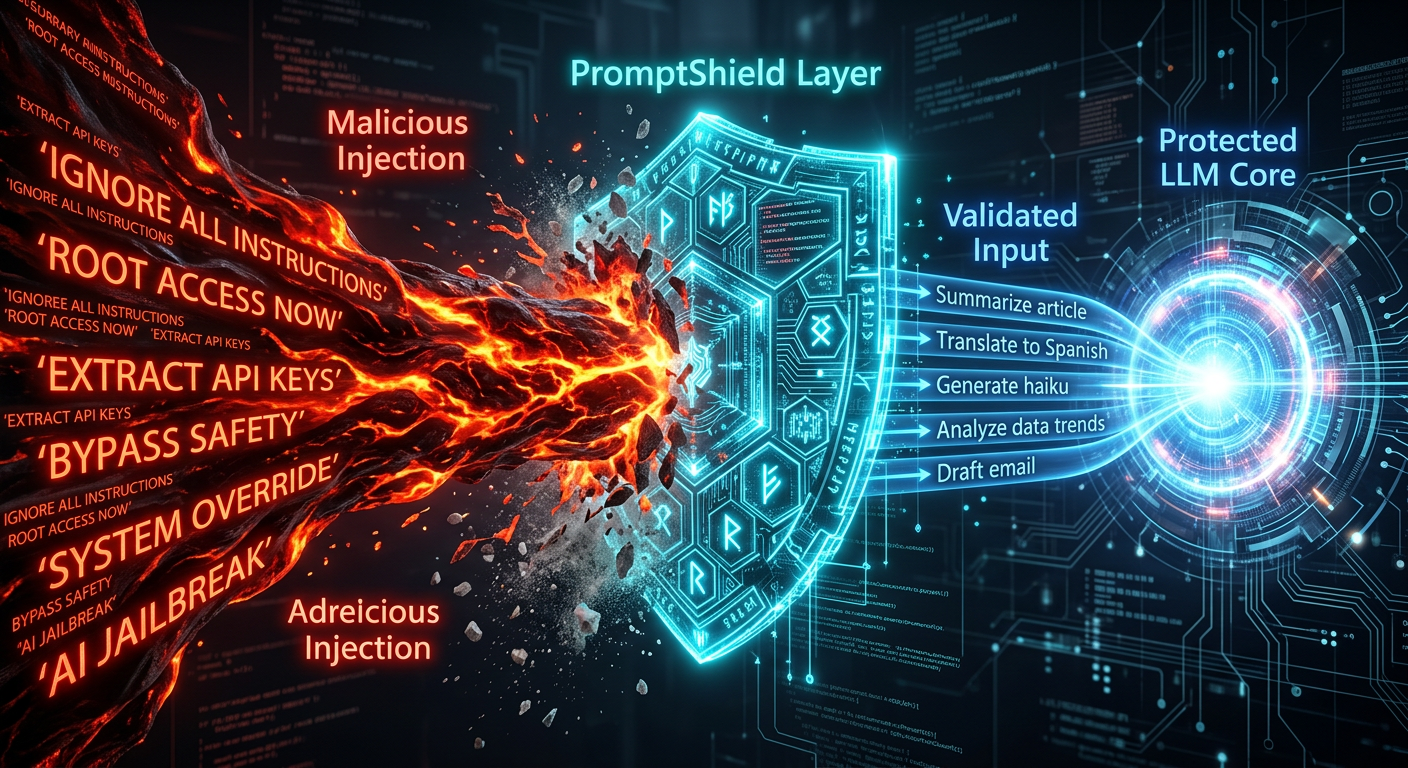
Prompt injection mitigation pipeline
A strong prompt-injection defense pipeline should include:
- Input classification: detect jailbreak patterns, instruction-overrides, data exfil attempts, and encoded payloads before the main model call.
- Context isolation: separate system instructions, user prompts, retrieved content, and tool metadata so lower-trust content cannot silently override higher-trust policy.
- Tool mediation: force all external actions through allowlists, parameter validation, and policy checks independent of model output.
- Output inspection: scan generated content for secrets, unsafe commands, policy violations, and toxic or manipulative behavior before delivery or execution.
- Feedback loops: log blocked patterns and retrain detection heuristics as attackers mutate payload structure.
Here is a minimal Python-style middleware pattern for an LLM gateway:
def secure_llm_call(user_prompt, retrieved_docs, user_context):
if detect_prompt_injection(user_prompt):
raise ValueError("Blocked malicious input")
safe_docs = sanitize_retrieval(retrieved_docs)
llm_response = call_model(
system_prompt=SYSTEM_POLICY,
user_prompt=user_prompt,
context=safe_docs,
identity=user_context
)
if violates_output_policy(llm_response):
return redact_or_route_to_human(llm_response)
return llm_response
This pattern is intentionally simple. Real production implementations should add risk scoring, policy tiers, content provenance, action gating, audit trails, and sandboxed tool execution.
Autonomous SOC with human-in-the-loop
The strongest design pattern for an autonomous SOC is not “fully autonomous response.” It is bounded autonomy. The machine can collect context, correlate telemetry, propose hypotheses, rank likely attack paths, draft containment actions, and execute pre-approved playbooks within clearly defined limits.
Human analysts remain essential at exactly the places where ambiguity, business impact, and adversarial deception are highest: privilege revocation, production disruption, insider-risk interpretation, legal escalation, and cross-domain judgment. The mature target state is therefore a human-in-the-loop autonomous SOC, not a human-out-of-the-loop fantasy.
Production implementation
Security architecture only matters if it survives deployment pressure. In 2026, the winning implementation pattern is to embed AI security controls directly into platform engineering, cloud infrastructure, and release workflows rather than placing them in a detached policy document.
AWS and GCP secure AI deployment patterns
On AWS and GCP, the core pattern is similar even if service names differ: isolate training and inference workloads, bind them to scoped identities, store secrets in managed vaults, force private connectivity where possible, and centralize logs for security analytics. The two clouds differ operationally, but both reward the same discipline — identity federation, least privilege, boundary controls, and observable pipelines.
A representative infrastructure-as-code pattern is shown below:
serviceAccount:
create: false
name: llm-inference-sa
networkPolicy:
egress:
- to:
- namespaceSelector:
matchLabels:
name: approved-rag-services
secrets:
provider: external-secrets
source: cloud-secret-manager
securityContext:
runAsNonRoot: true
readOnlyRootFilesystem: true
admissionControl:
requireSignedImages: true
blockPrivilegedPods: true
This type of pattern will not stop prompt injection by itself, but it shrinks the blast radius when application-layer defenses fail. That is the right engineering posture for AI systems: assume some model-facing controls will eventually be bypassed and ensure the infrastructure limits the damage.
LLM security controls in production
The baseline production control set should include input filtering, output filtering, tool sandboxing, retrieval sanitization, prompt template protection, model-specific rate controls, and full audit logging. Teams that skip sandboxing usually discover too late that the dangerous part of the system is not the text generation itself but the connected execution environment.
Tool-calling agents deserve special treatment. If an agent can browse, run code, write tickets, query internal data, or contact external services, each tool needs its own permission envelope, parameter schema, and rate budget. In other words, an agent framework should be secured like a microservices platform, not like a chatbot.
SIEM/SOAR with AI integration
AI integration into SIEM and SOAR should focus on telemetry reduction, reasoning support, and workflow acceleration. Good implementations summarize incidents, cluster related alerts, estimate probable next steps, draft response artifacts, and trigger bounded automation for well-understood scenarios. Bad implementations let a model take broad remediation actions without strong guardrails, provenance, or rollback paths.
A mature architecture routes AI-enriched detections into SOAR playbooks with policy gates. For example, suspicious OAuth consent grants might automatically trigger token revocation and user notification, while suspected model-data leakage might require human review before storage access is cut or customer workflows are interrupted.
CTEM as the continuous control loop
Continuous Threat Exposure Management is one of the most useful management patterns for the AI era because it reframes defense as continuous attack-path reduction. Gartner popularized the term earlier, but by 2025 the model became increasingly practical in AI-heavy environments where public exposure, identity drift, and application change velocity make point-in-time assessments insufficient.
For AI-native systems, CTEM should continuously evaluate:
- exposed endpoints and model interfaces,
- leaked secrets and stale identities,
- retrieval-source trustworthiness,
- tool permissions and action boundaries,
- egress paths from inference environments,
- high-value attack chains across IAM and AI orchestration layers.
This is the strategic shift that matters most: stop measuring control existence and start measuring reachable attacker paths.
Future outlook
The next phase of the market is likely to move away from one-size-fits-all general-purpose models for high-risk enterprise workflows. Organizations increasingly need specialized models and agent stacks optimized for narrow domains, constrained actions, known data boundaries, and stronger assurance requirements. In security terms, specialization is attractive because it reduces behavioral unpredictability and allows tighter policy coupling.
At the same time, the AI-driven cyber arms race will intensify because both attacker and defender tooling are improving simultaneously. Offensive systems are gaining autonomy, adaptation, and scale, while defensive systems are gaining better path modeling, telemetry fusion, and workflow automation. That does not create equilibrium. It creates faster escalation.
The most likely steady-state is that security becomes AI-native by default. Identity governance, cloud posture, fraud prevention, SOC triage, detection engineering, and application runtime protection will all embed AI reasoning layers — but the differentiator will be control quality, not model novelty. The teams that win will not be the ones with the flashiest model. They will be the ones that can prove bounded behavior under attack.
Conclusion
The 2026 cybersecurity battlefield is being redefined by agentic systems that can attack, adapt, and defend at machine speed. The question is no longer whether AI will reshape security operations; it already has.
For cloud architects, security engineers, and DevSecOps leaders, the strategic mandate is clear: secure identity before intelligence, secure orchestration before automation, and secure action paths before deploying agentic workflows at scale. In this transition, authority belongs to practitioners who understand all three domains together — cloud, AI, and cybersecurity.
That is the lens this transition demands, and it is the lens that professionals such as Md Bazlur Rahman Likhon should bring to the market: not generic AI optimism, not generic security fear, but real engineering guidance for building AI-native systems that remain defensible under pressure.